
Calculatrice de Test d'Hypothèse Statistique
Cette calculatrice de test d'hypothèse statistique détermine si une autre hypothèse est vraie ou non. La question de savoir si elle est vraie ou non détermine si nous acceptons ou rejetons l'hypothèse. Nous acceptons les hypothèses vraies et rejetons les hypothèses fausses.
L'hypothèse nulle est l'hypothèse qui est revendiquée et que nous allons tester contre.
L'hypothèse alternative est l'hypothèse que nous croyons qu'elle est réellement.
Par exemple, disons qu'une entreprise affirme qu'elle ne reçoit que 20 plaintes de consommateurs en moyenne un an. Cependant, nous croyons que très probablement il reçoit beaucoup plus. Dans ce cas, l'hypothèse nulle est l'hypothèse revendiquée par la société, que les plaintes moyennes est de 20 (μ = 20). L'hypothèse alternative est que μ> 20, ce que nous soupçonnons. Donc, quand nous faisons nos tests, nous voyons quelle hypothèse est réellement vrai, le null (réclamé) ou l'alternative (ce que nous croyons qu'il est).
Le niveau de signification que vous sélectionnez déterminera la largeur d'une région de la région de rejet sera. Le niveau de signification représente la région de rejet total d'une courbe standard normale. Par conséquent, si vous choisissez de calculer avec un niveau de signification de 1%, vous choisissez une distribution normale normale qui a une région de rejet de 1% du total 100%. Si vous choisissez un niveau de signification de 5%, vous augmentez la région de rejet à 5% des 100%. Si vous choisissez un niveau de signification de 20%, vous augmentez la région de rejet de la courbe normale à 20% des 100%. Plus vous augmentez le niveau de signification, plus la région de rejet est grande. Cela signifie qu'il ya une plus grande chance qu'une hypothèse sera rejetée et une chance plus étroite que vous avez d'accepter l'hypothèse, puisque la région non-réjection diminue. Ainsi, plus le niveau de signification est élevé, plus la région de non-réjection est petite ou plus étroite. Plus le niveau de signification est faible, plus la région de non-rejet est grande.
Il existe 3 types de tests d'hypothèse que nous pouvons faire.
Il ya queue gauche, queue droite, et test de deux hypothèses de queue.
Test de l'Hypothèse Statistique Unilatéral à Gauche
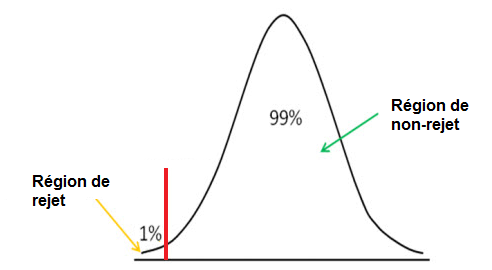
Le test des hypothèses unilatéral à gauche est illustré ci-dessous:
Nous utilisons des tests d'hypothèse unilatéral à gauche pour voir si le score z est au-dessus du point de coupure de niveau de signification, auquel cas nous acceptons l'hypothèse nulle comme vraie.
La méthode du test unilatéral à gauche, tout comme le test unilatéral à droite, a un point de coupure. Le niveau de signification que vous choisissez détermine ce point de coupure. Toute valeur inférieure à ce seuil dans la méthode de queue gauche représente la région de rejet. Cela signifie que si nous obtenons un score z en dessous du point de coupure, le score z sera dans la région de rejet. Cela signifie que l'hypothèse est fausse. Si le score z est au-dessus du point de coupure, cela signifie qu'il est dans la région de non-rejet, et nous acceptons l'hypothèse comme vraie.
La méthode du test unilatéral à gauche est utilisée si nous voulons déterminer si la moyenne d'un échantillon est inférieure à la moyenne de l'hypothèse. Par exemple, disons que la moyenne de l'hypothèse est de 40 000 $, ce qui représente le salaire moyen des travailleurs de l'assainissement et nous voulons déterminer si ce salaire a diminué au cours des dernières années. Cela signifie que nous voulons voir si la moyenne de l'échantillon est inférieure à la moyenne de l'hypothèse de 40 000 $. Il s'agit d'un test classique de l'hypothèse de la queue gauche, où la moyenne de l'échantillon,
Test de l'Hypothèse Statistique Unilatéral à Droite
Le test de l'hypothèse unilatéral à droite est illustré ci-dessous:
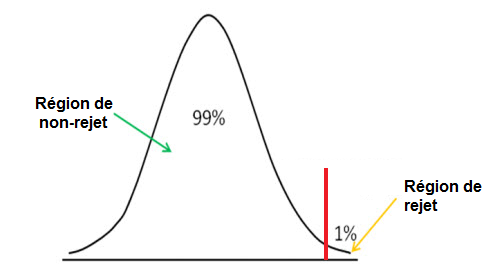
Nous utilisons des tests d'hypothèse unilatéral à droite pour vérifier si le score z est inférieur au seuil de seuil de signification, auquel cas nous acceptons l'hypothèse nulle comme étant vraie.
La méthode du test unilatéral à droite, tout comme le test unilatéral à droite, a un point de coupure. Le niveau de signification que vous choisissez détermine ce point de coupure. Toute valeur au-dessus de cette coupure dans la méthode de la queue droite représente la région de rejet. Cela signifie que si nous obtenons un score z au-dessus du point de coupure, le score z sera dans la région de rejet. Cela signifie que l'hypothèse d'hypothèse nulle est fausse. Si le score z est inférieur au point de coupure, cela signifie qu'il est dans la région de nonréjection, et nous acceptons l'hypothèse comme vraie.
La méthode unilatéral à droite est utilisée si nous voulons déterminer si une moyenne d'échantillon est supérieure à la moyenne d'hypothèse. Par exemple, disons qu'une entreprise affirme qu'elle a 400 accidents de travail par an. Cela signifie que l'hypothèse nulle est de 400. Cependant, nous soupçonnons qu'il ya beaucoup plus d'accidents que cela. Par conséquent, nous voulons déterminer si ce nombre d'accidents est plus élevé que ce qui est réclamé. Cela signifie que nous voulons voir si la moyenne de l'échantillon est supérieure à la moyenne des hypothèses de 400. Il s'agit d'un test classique de l'hypothèse de la droite, où l'échantillon a une moyenne de H0. C'est l'hypothèse alternative. L'hypothèse nulle est que la moyenne est de 400 accidents de travail par an. Et l'hypothèse alternative est que la moyenne est supérieure à 400 accidents par an. Si le score z calculé est supérieur au seuil de signification, cela signifie que nous rejetons l'hypothèse nulle et acceptons l'hypothèse alternative, car la moyenne de l'hypothèse est beaucoup plus faible que ce que la moyenne réelle est réellement. Par conséquent, il est faux et l'hypothèse alternative est vraie. Cela signifie qu'il y a vraiment plus de 400 accidents de travail par an et que l'allégation de la compagnie est inexacte. Si le score z est inférieur au seuil de seuil de signification, cela signifie que nous acceptons l'hypothèse nulle et rejetons l'hypothèse alternative qui l'affirme plus, parce que la moyenne réelle est effectivement inférieure à la moyenne de l'hypothèse. Cela signifie vraiment qu'il ya moins de 400 accidents de travail par an et la réclamation de l'entreprise est correcte.
Test de l'Hypothèse Statistique Bilatéral
Le test d'hypothèse bilatéral sont illustrés ci-dessous:
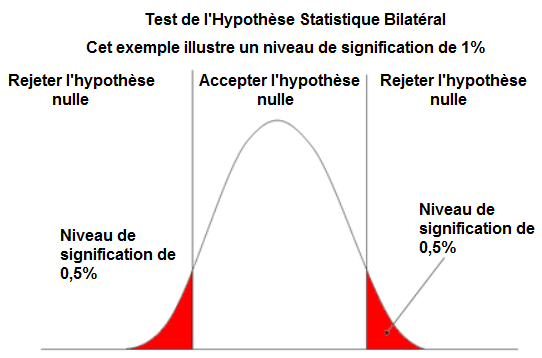
Nous utilisons la méthode bilatéral pour voir si la moyenne de l'échantillon réel n'est pas égale à ce qui est revendiqué dans la moyenne de l'hypothèse.
Ainsi, si la moyenne de l'hypothèse est revendiquée comme étant de 100. L'hypothèse alternative peut prétendre que la moyenne de l'échantillon n'est pas de 100.
La méthode bilatéral a 2 points de coupure. Le niveau de signification que vous choisissez détermine ces points de coupure. Si vous choisissez un niveau de signification de 1%, les 2 extrémités de la courbe normale comprendront chacune 0,5% pour constituer le niveau de signification complet de 1%. Si vous choisissez un niveau de signification de 5%, les 2 extrémités de la courbe normale comprendront chacune 2,5% pour constituer les extrémités.
Si le score z calculé est entre les 2 extrémités, nous acceptons l'hypothèse nulle et rejetons l'hypothèse alternative. C'est parce que le score z sera dans la région de non-rejet. Si le score z est en dehors de cette plage, alors nous rejetons l'hypothèse nulle et acceptons l'alternative parce qu'elle est en dehors de la plage. Par conséquent, la moyenne de l'échantillon est réellement différente de la moyenne de l'hypothèse nulle, qui est la moyenne revendiquée.
Pour utiliser cette calculatrice, un utilisateur sélectionne la moyenne de l'hypothèse nulle (la moyenne revendiquée), la moyenne de l'échantillon, l'écart-type, la taille de l'échantillon et le niveau de signification et clique sur le bouton «Calculer». La réponse résultante sera automatiquement calculée et représentée ci-dessous, avec une explication quant à la réponse.
Le test d'hypothèse peut être utilisé pour tout type de science pour montrer si nous rejetons ou acceptons une hypothèse basée sur l'informatique quantitative. Même dans certains domaines de l'électronique, cela pourrait être utile.
Ressources Connexes
Calculatrice de L'intervalle de Confiance
Calculatrice de L'inégalité de Bienaymé-Tchebychev
Calculatrice de L'inégalité de Bernoulli
Calculatrice de Chiffres Significatifs
Calculatrice de la Multiplication de Chiffres Significatifs
Calculatrice de Notation Scientifique
Calculatrice de Factorisation